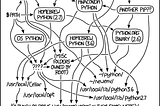
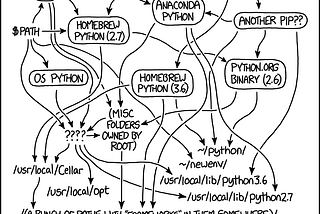
PinnedSalma El ShahawyinTowards Data ScienceHow to Set up Python3 the Right Easy Way!A comprehensive guide that helps data scientists to set up their python developmenvironment to share reproducible notebooks.·8 min read·Dec 12, 2020--9--9
Salma El ShahawyinGeek CultureHow to schedule the ETL jobs on AWS The Easy wayA step-by-step guide to automating data extraction jobs from the Ec2 in 5 minutes8 min read·Aug 5, 2021----
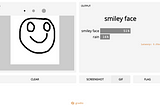
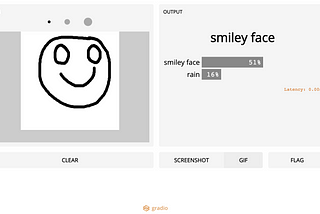
Salma El ShahawyinTowards Data ScienceHow to Create Machine Learning UIs the Easy WayHow I built a great UI for a complicated sketch recognition model·6 min read·Mar 6, 2021----
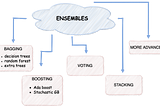
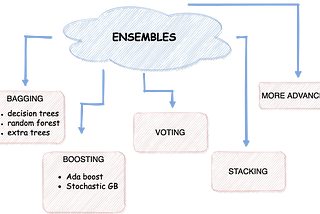
Salma El ShahawyinTowards Data ScienceHow to Get the Most of the ML EnsemblesLessons from Kaggle: Compare ensembles algorithms in terms of model accuracy, robustness, and generalization. Implementation included!·9 min read·Feb 13, 2021--2--2
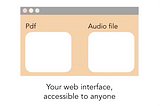
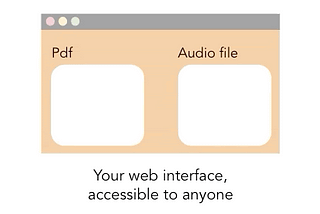
Salma El ShahawyinTowards Data ScienceBuild an Awesome UI for your Machine Learning ModelsA step-by-step guide for quickly building a great UI for a PDF-to-audiobook converter, deployment steps included.7 min read·Jan 29, 2021----
Salma El ShahawyinTowards Data ScienceHow to Get the Most of the Machine Learning ModelsLessons I learned from Kaggle to enhance the final model performance. Each evaluation strategy’s pros and cons and when to use each one…·7 min read·Jan 23, 2021----
Salma El ShahawyinTowards Data ScienceSetting up python environment using Github actions.This article aims to automate the machine learning projects hosted on GitHub and reducing code breaking via pull requests.·6 min read·Jan 2, 2021----
Salma El ShahawyinTowards Data ScienceMultiprocessing and Pickle, How to Easily fix that?This article will discuss the proper ways for serialization considering multiprocessing tasks. The more robust serialization package dill…·6 min read·Dec 19, 2020--1--1
Salma El ShahawyinTowards Data ScienceHow To Rock A categorical encoding That Will Save You Tons Of TimeA comparison between categorical encoding strategies. This guide aims to assist you picking the right strategy based on your application.·7 min read·Dec 7, 2020--1--1
Salma El ShahawyinTowards Data ScienceHow to deploy your first Machine learning models — Part#2Deploy the Machine Learning API to Heroku using the CircleCI pipeline with fewer command.·9 min read·Nov 11, 2020----